本文为本人UCAS的课程论文阅读报告,禁止转载!!!
本文为本人UCAS的课程论文阅读报告,禁止转载!!!
本文为本人UCAS的课程论文阅读报告,禁止转载!!!
# 团队介绍
# 本文作者
Chunlin Xiong:中国科学院深圳先进技术研究院和深信服联培博士后,主要研究APT检测和取证分析,其作为第一作者曾在2022年TDSC期刊中发表论文Conan: A Practical Real-Time APT Detection System With High Accuracy and Efficiency
Jiacen Xu和Zhou Li:加州大学,主要研究域名系统安全、基于日志的异常检测、隐私保护、机器学习安全和隐私
Fan Yang和Kehuan Zhang:香港中文大学,主要研究二进制代码安全分析
# 领域内主要研究团队
在Provenance graph-based detectors for APTs(基于溯源图的APT威胁检测)领域内,主要有以下三个团队:
-
伊利诺伊大学芝加哥分校团队:该团队于USENIX’17提出的
SLEUTH,将溯源图应用于APT攻击检测领域。在2019年CCS会议上提出Poirot,在S&P’19上提出Holmes,该方法融合了Kill Chain和ATT&CK框架。此外,在2021年EurS&P提出Extrator,并引入外部知识。 -
伊利诺伊大学香槟分校团队:该团队分别在NDSS’20提出了
UNICORN和ProvDetector,同时在2020年的S&P上提出RapSheet,它融合了ATT&CK框架。 -
普渡大学团队:该团队的核心成果包括NDSS’13提出的
BEEP,NDSS’16提出的ProTracer和USENIX’21提出的ATLAS。
# 选题背景
计算系统防御与攻击之间长期存在的战争不断演变,尽管入侵检测系统(IDS)和反恶意软件等防御措施已得到广泛部署,但以高级持续威胁(APT)为主题的复杂攻击仍然能够渗透组织网络,造成严重损害。抵御 APT 攻击失败的主要原因是:
- 传统防御系统依赖于攻击者可以轻松更改的攻击特征
- 传统防御系统没有充分利用计算系统或网络中不同实体之间的因果关系执行检测(例如,在系统日志上)。
为了解决这两个基本问题,近期基于数据溯源的防御系统被开发出来。数据溯源将系统日志转化为图形表示,捕获了不同类型实体(例如,进程和文件)之间的时间和因果关系。在这个表示上,可以执行图遍历等图操作来检测正在进行的攻击或推理入侵的根本原因。有了数据溯源,由于日志中嵌入的丰富上下文信息得到了很好的利用,因此检测APT攻击成为可能。
但是现有的所有基于溯源的系统都无法满足复杂生产环境中的所有基本部署要求,包括检测精度、运行时效率、“无签名”和细粒度。
- 依赖签名、启发式或已知攻击痕迹的溯源系统(Atlas、RapSheet、Homles)在攻击者调整他们的模式后可以被规避。
- 一些系统选择从日志中构建一个单一的溯源图并检测恶意实体和事件(Shadewatcher),但是当需要分析大量日志时,这种开销将变得过于昂贵,同时在这样的设置下也会生成大量的误报。
- 少数系统以流式方式从日志中构建时间有序的快照,并试图检测异常快照(Unicorn),但由于分析师必须分析异常快照内的所有实体/交互,所以检测粒度过于粗糙。
# 用于攻击调查的数据溯源
为了实现攻击检测和取证,系统日志通常由系统级审计工具收集,例如 Windows ETW、Linux Audit和 FreeBSD Dtrace,它们描述了系统实体(如进程和进程)之间的交互。文件。在组织内的终端主机上收集的日志通常由安全信息和事件管理 (SIEM) 等中央服务进行分析,以检测复杂的跨机器攻击。
除了系统日志之外,还提出了数据来源来检测和推理入侵,甚至包括多个阶段(例如侦察、安装、命令和控制以及横向移动)的长期高级持续威胁(APT)攻击可以检测到。本质上,数据溯源从系统日志构建依赖图来描述事件之间的关系,因此检测和调查可以转化为与图相关的操作。
在所有与图相关的操作中,图遍历可能是最受欢迎的选择。一个突出的例子是回溯,安全分析师通过回溯查询带有兴趣点(POI)实体和时间窗口的来源图,并返回具有时间依赖性的事件。然而,这种简单的方法会遇到“依赖爆炸”,这可能是由在其生命周期内与许多主体/对象交互的长时间运行的进程引起的。
# 基于学习的溯源图攻击检测
为了准确定位攻击事件,人们提出了大量基于规则的方法,这些方法利用已知攻击行为的知识来搜索溯源图。然而,编写规则需要分析师付出相当大的努力,并且可能会错过不可见模式下的攻击。因此,最近基于学习的方法,即训练具有正常系统行为(以及监督学习的恶意行为)的模型来检测异常系统执行,开始获得更多关注。尽管应用基于学习的方法来捕获网络攻击并不新鲜,但溯源图引入了利用图结构和应用新的图学习方法的新机会。现有的工作可以按照目标的粒度进行分类:边/节点、路径和图。
# 图嵌入
为了捕获溯源图的关键属性,溯源系统通常使用图嵌入。在社交网络、推荐系统和生命科学等其他领域,图嵌入在提高图分类、聚类和回归等下游任务的性能方面取得了显着的成功。本质上,图嵌入学习用低维向量来表示节点、边、子图或整个图,这些低维向量捕获图结构、点到点关系以及有关图的其他相关信息。溯源系统利用了两种类型的图嵌入技术:
节点嵌入将图的每个节点映射到一个低维向量,该向量保留其关键信息,例如节点的邻域信息、节点的结构角色和节点的状态。流行的节点嵌入模型包括 DeepWalk 、GCN 、GraphSage 等。可以执行与基于节点、边和路径的检测相关的节点分类和边分类等下游任务,通过计算节点嵌入的节点/边分数并将其与阈值进行比较。
全图嵌入用单个向量表示整个图,该向量聚合来自节点表示的信息。流行的全图嵌入模型包括DiffPool、graph2vec、graph sketching等。与基于图的检测相关的图分类和聚类等下游任务可以通过图向量的计算来执行。
边缘嵌入也被提出用于社交网络中的推荐等应用,但目前还没有发现它被任何溯源系统使用
# 方法陈述
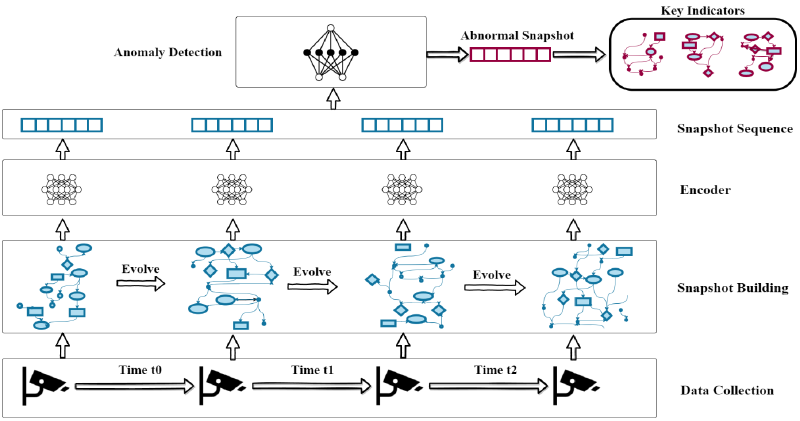
在本文中,作者提出了 PROGRAPHER,一种新的基于来源的异常检测系统,它同时满足检测精度、运行时效率、“无签名”和细粒度的要求。PROGRAPHER在图粒度上进行检测,当日志被摄取时,PROGRAPHER 会提取快照以减少整个来源图的计算和内存成本。在每个快照上,PROGRAPHER 应用名为 graph2vec 的全图嵌入技术来生成有根子图(RSG)作为每个节点的低维表示,并通过最大化正常快照和正常RSGs共现可能性来学习图表示。为了捕获快照之间的时间动态,采用了名为 TextRCNN 的序列学习模型,因此可以预测未来快照的表示,并在偏离预测时检测到异常快照。以前的系统(如 Unicorn)停留在报告异常快照的阶段,但 PROGRAPHER 通过对 RSG 进行排名并将最可疑的实体报告为攻击指标来继续查明异常实体。
# 概述
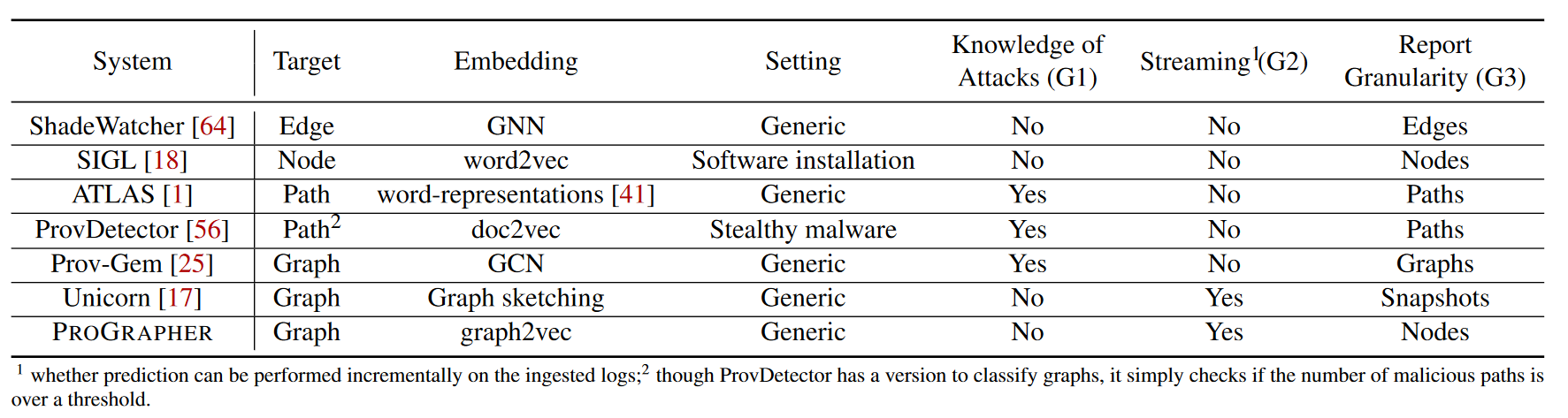
本文设想 PROGRAPHER 要实现三个的设计目标(G1 - G3)。值得注意的是,之前的方法都无法满足所有这些要求,本文将 PROGRAPHER 与表1中的其他代表性方法进行比较。
G1:PROGRAPHER 应该从良性日志中学习正常行为模式,因此它增加了检测利用零日漏洞的攻击的机会。换句话说,PROGRAPHER 应该通过无监督学习来构建,而不需要任何攻击或事件标签的知识。
G2:由于长时间处理溯源图非常消耗资源,PROGRAPHER应该能够处理整个起源图的由周期分隔的子图,并利用周期之间的时间动态进行检测。
G3:PROGRAPHER应该能够准确识别活动异常的子图。此外,PROGRAPHER 应该指出与攻击直接相关的实体,从而缩小了调查范围。
PROGRAPHER 由四个组件组成以满足 G1-G3:
-
快照构建器
-
编码器
-
异常检测器
-
关键指标生成器
PROGRAPHER 的工作流程如图1所示,快照构建器首先从终端主机收集的审核日志中提取节点和边,然后根据时间戳将数据分割成快照。编码器生成嵌入在每个快照上的整个图,以捕获图的结构特征。异常检测器使用应该仅包含良性活动的快照的嵌入来训练预测模型,并检测异常快照。最后,关键指标生成器对异常快照包含的节点进行排序,并将排名靠前的节点报告给分析人员。

# 快照构建器
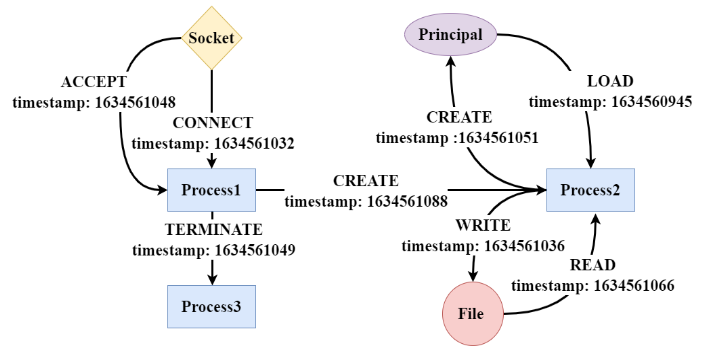
本文考虑有关文件(例如文件创建、文件读取、文件写入)、进程(例如创建和权限更改)、网络套接字(例如网络连接)、主体(用户或帐户)等的日志事件。边由描述源实体对目标实体执行的操作的事件组成(例如,进程读取文件)。图 2 显示了一个示例。
PROGRAPHER 考虑的节点类型和边类型的完整列表如表2 所示。

为了有效地处理大量传入日志,PROGRAPHER 构建按时间排序的快照。当日志被摄取时,它会维护一个缓存图。对于每个传入日志,当事件源和目标不可见时,它们将作为节点添加到缓存图中,在这对新节点之间还会创建一条边,并将日志时间戳分配给这些节点。对于一对现有节点,它们的时间戳会被更新。当节点数达到n(也称为快照大小)时,所有n个节点和它们的边会被保存到第一个快照中。之后,PROGRAPHER 从传入日志中添加新节点,使用遗忘率(fr)淘汰 $n × fr$ 个最旧的节点,并在节点数量达到 $n × (1 + fr)$ 时将缓存图保存到新快照中。这样使得一对相邻的快照在节点中总是有 $n × (1 − fr) $重叠。
重复这个过程来生成一系列快照${S_1,S_2,…, S_k}$。通过这样的设计,确保可以通过比较相邻快照来恢复时间动态,并且每个快照的大小受到控制。此外,快照中良性和恶意痕迹之间的比率预计将比整个溯源图小得多,从而解决数据不平衡问题。伪代码如算法1所示。

# 编码器
(1) 枚举每个节点以提取不同度数的RSG,从而捕获节点的邻域信息。在graph2vec中,利用Weisfeiler-Lehman(WL)graph kernels来测试图同构性来实现这一目标。具体来说,对于节点 v,WL 内核将其标签及其连接的边和节点的标签作为输入标签,然后,为从输入标签聚合而来的 v 生成一个新标签,称为 RSG。整个过程在每个节点$ v ∈ V$ 上重复 d 次,以描述其深度为 $1, …, d$ 的邻域。
为了适应起源图的格式,本文将节点和边类型视为标签(原始 WL 内核仅考虑节点类型)。此外,作者发现从大而密集的图生成的RSG可能有很多冗余标签,为了提高效率,本文只保留每个 RSG 的唯一标签。在算法2中描述了RSG生成的步骤。作为一个具体示例,图 2 中 d = 0, 1, 2 时节点“Process2”的 RSG 为:
- d = 0: [(Process)].
- d = 1: [(Process), (File), (Principal), LOAD, WRITE, CREATE, READ].
- d = 2: [(Process, File, Principal, LOAD, WRITE, CREATE, READ), (Process, Principal, LOAD, CREATE), (Process, File, READ, WRITE), (Process, Socket, CREATE, CONNECT, TERMINATE, ACCEPT), LOAD, WRITE, CREATE, READ].

(2) 生成快照$S_i$的嵌入$E_{S_i}$。$E_{S_i}$被初始化为随机向量,然后通过最大化所有节点的 RSG 的对数似然来更新,这些节点也由嵌入表示。所有快照${S_1,S_2,…, S_k}$的嵌入E可以通过梯度下降一起更新。更新过程遵循doc2vec使用的skipgram模型。将目标函数定义为:
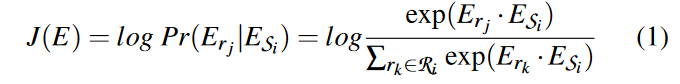
为了训练效率,本文像基于无监督学习的先前工作一样应用负采样。在快照 $S_i$ 上,从整个子图集中随机选择 m 个 RSG $R ′ _i= {r_1, r_2, ··· , r_m}$ 作为负样本,使得 $R′_i\cap R_i \neq 0$。目标函数 J(E ) 将被调整以最大化 $R_i $的对数似然并同时最小化 $R′_i$ 的对数似然。由于$R′_i$ 是不存在的 RSG 的子集,因此减少了训练开销。算法3中总结了嵌入生成的整个过程。

# 异常检测器
生成快照的表示后,PROGRAPHER 继续检测异常快照。将快照之间的变化视为检测的重要输入,并一起检查快照序列${S_1,S_2,…, S_k}$,该任务选择了已广泛用于文本分类的 TextRCNN 提出的双向循环结构和卷积神经网络模型。
为了训练异常检测器,本文将一组快照序列及其相关的嵌入作为输入。使用循环结构和卷积网络来获得输入序列中每个快照$S_i$的潜在表示$y_i$,其定义如下:
![]()
其中$x_i=[left(S_i);E(S_i);right(S_i)]$是左侧上下文向量、其自身的嵌入和右侧上下文向量的串联。 W 是权重矩阵,b 是偏差向量。左右上下文向量定义为:
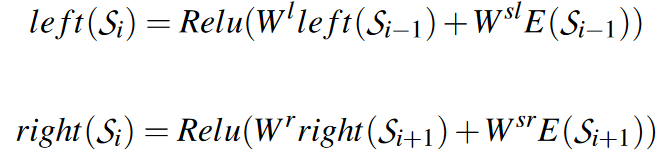
利用 maxpool 层和全连接层来获得每个快照序列的最终表示
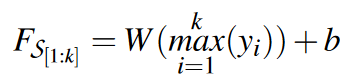
在训练阶段,给定一个快照序列${S_1,S_2,…, S_k}$,我们预测该序列与其后续快照 $S_{k+1}$ 相关的可能性有多大。将损失定义为 L2 距离的距离,如下所示:
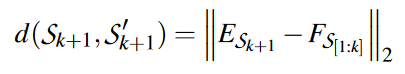
其中$E_{S_{k+1}}$是快照$S_{k+1}$的嵌入。在测试阶段,给定快照序列,将其预测嵌入与真实嵌入进行比较。如果它们之间的距离超过预先定义的阈值,则将其标记为异常。
# 关键指标生成器
检测到异常快照后,将生成恶意活动的关键指标。作者发现 Unicorn等其他作品缺失了这一步。因此,他们的检测结果是粗粒度的。但随着 graph2vec 的采用,PROGRAPHER 可以实现更细粒度的攻击归因。
目标函数 J(E) 测量快照嵌入与每个 RSG 之间的共现概率,其值越小,共现概率越小。由于可能性是根据快照的每个 RSG 计算的,因此可以按 RSG 的概率对 RSG 进行排序,并从中选择关键指标。特别是,在测试阶段,给定快照$S_i$,将从 $S_i$ 生成的嵌入 $E_{S_i}$ 与从 k 个快照序列预测的嵌入$E’_{S_i}$进行比较,并提取每个 RSG 的两个嵌入之间的差异。之后,根据损失差异对RSG进行排序,并选择前K个可疑RSG。 RSG 可以映射到多个节点,因为它只存储节点和边类型。因此,系统搜索快照以找到与 K 个可疑 RSG 匹配的所有节点,并将它们反馈给分析师。
# 实验开展及结果
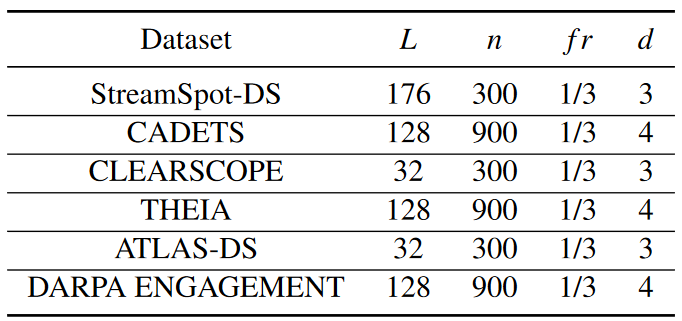
为了确保每个快照包含足够的信息来学习其表示,作者根据数据集的规模设置快照大小 n。对于节点数小于 10K 的小图(例如机器上软件的溯源图),n 设置为 300。对于节点超过10k的大图(例如操作系统的溯源图),n 设置为 900对于不同的数据集,L 配置为 32、128 和 176。在快照构建过程中,使用遗忘率 fr 设置为 1/3。对于编码器和异常检测器,本文通过网格搜索选择超参数,它们的最佳值如下表3 所述。
训练和测试在一台配备 32 核 Intel E5-2640 处理器、256 GB 物理内存和 1 个 Nvidia GTX TITAN X GPU 的服务器上进行,操作系统是Ubuntu 14.04.6 LTS。
# 数据集
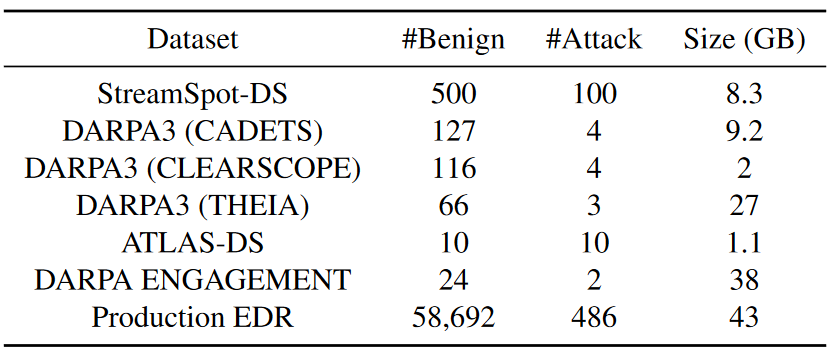
本文使用两个具有模拟攻击的日志数据集(StreamSpot 和 ATLAS)和两个 DARPA 数据集(DARPA3 和 DARPA ENGAGEMENT)来评估 PROGRAPHER 的实际表现。此外,本文在生产环境中部署PROGRAPHER来分析商业EDR产品收集的系统日志。如下表4所示展示的数据集统计,“#Benign”和“#Attack”是良性图和攻击图的数量。大小是在预处理后的图表上测量的,而不是原始数据。每个数据集都通过训练、验证和测试分开,在实验中确保所有数据集都是不相交的,并且在测试集中所有的良性图都发生在训练和验证图之后。
# 有效性评估
表5展示了在100次重复实验情况下,Sreamspot-DS和DARPA3的实验结果,以Unicorn为baseline,本文的ProGrapher方法在精确率、召回率、准确率和F1值上具有更好的表现。
Unicorn结果比论文上报告的结果更差,主要原因为:
- 从Unicorn作者那里了解到,他们使用了 DARPA TC 下的非公开良性数据集进行训练,而本文作者无法访问该数据集。
- Unicorn实现并没有强制测试中的图在训练和验证之后发生,这是安全系统中的常见“数据窥探”问题[5]。
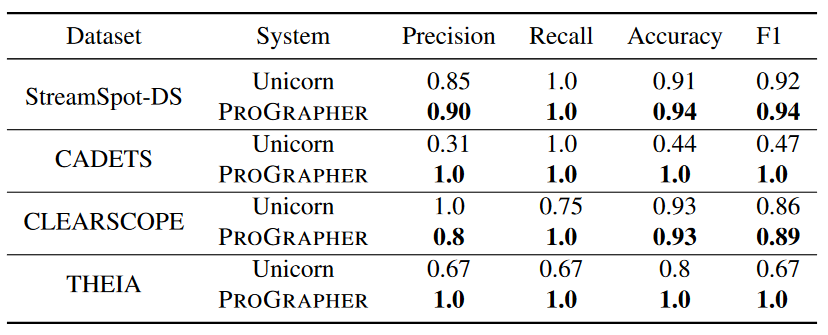
仅将 CLEARSCOPE 中的一个良性图错误地检测为异常。FP主要是由于训练集中的行为信息不足造成的,由于作者只保留同一对实体的最新事件,因此对于 CLEARSCOPE,每个实体对可以删除数百个事件。这种策略删除了可以区分良性和恶意行为的有用信息,这也解释了为什么预处理后CLEARSCOPE数据集的大小很小(只有2GB)。
表 6 展示了ProGrapher在ATLAS-DS和 DARPA ENGAGEMENT数据集上的表现,ProGrapher系统成功检测到所有攻击并且不生成任何 FP,结果还表明PROGRAPHER可以处理不同类型的APT攻击。

在Production EDR的实验结果。按端点从 180GB 日志中提取了大约 59K 个图表。从前 7 天开始,作者使用 51119 个良性图进行训练(良性图由分析师选择),并使用 2889 个良性图进行验证。在剩下的 2 天里,我们使用 4684 个良性图和 486 个攻击图进行测试。
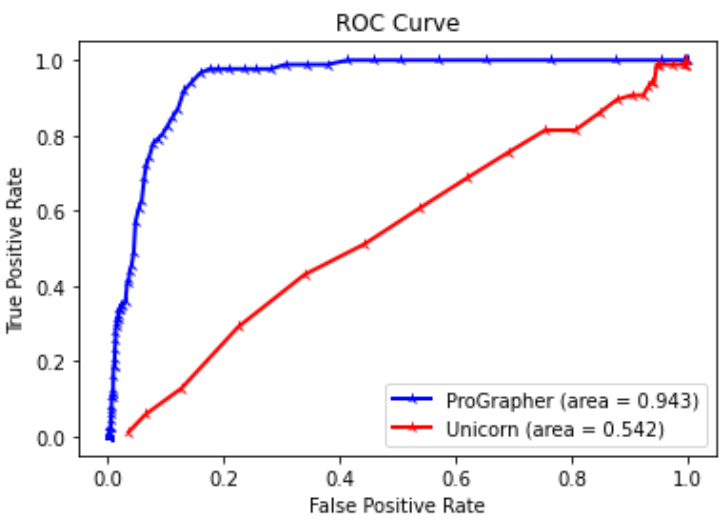
在图3中,作者绘制ROC曲线来说明TPR和FPR之间的关系,并与Unicorn进行比较。结果表明 PROGRAPHER 在生产环境中可以达到合理的精度,例如 94% TPR、14% FPR。 Unicorn 的检测精度明显降低,低于 PROGRAPHER,例如,在 20% FPR 时,TPR 低于 10%。 PROGRAPHER 的曲线下面积 (AUC) 几乎是 Unicorn 的两倍(0.943 vs. 0.542)。
# 生成指示器评估
指示器的有效性。 ProGrapher方法从异常快照中选择前K个RSG,并反馈与这些RSG匹配的所有节点。给定一个真实的攻击节点,我们认为 3 跳邻域中的节点是有效的,而所有其他节点是无效的。
本文选择 3 跳邻域,因为本文中将小图的 WL 内核深度设置为 3(大图为4),因为在给出警报的情况下调查邻域实体是一种常见做法,如果指标中至少有一个节点属于攻击节点或有效邻居,则认为该指标有效。
将有效率计算为有效指标与 PROGRAPHER 识别的所有指标之间的比率。表 7 显示了 3 个 DARPA3 子集的不同 K(从 1 到 5)的比率。可以看到,即使 K 值在 2 到 3 之间,有效率也已经相当高了(至少 0.94)。
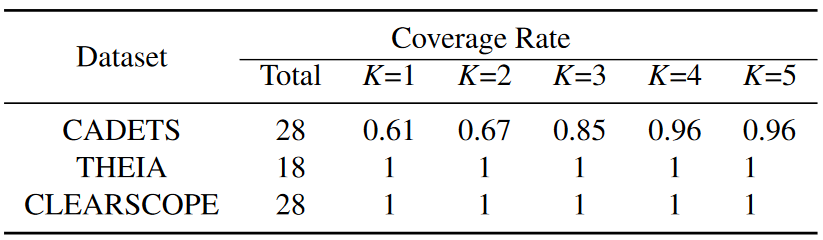
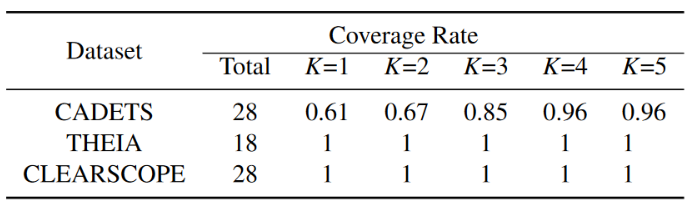
将覆盖率定义为正确识别的攻击节点与所有真实攻击节点之间的比率。表 8 显示了 K 范围为 1 到 5 的每个数据集的覆盖率,对于 THEIA 和 CLEARSCOPE 数据集,所有攻击节点均得到识别,对于 CADETS,当 K ≥ 4 时,仅丢失 1 个攻击节点。
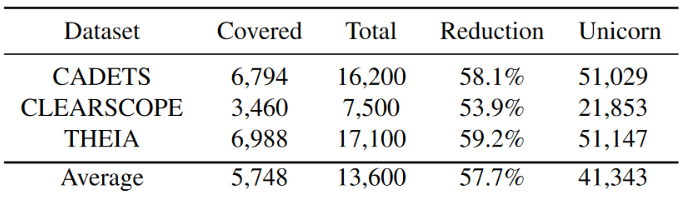
将缩减率定义为 1 − Covered/Total(“Covered”和“Total”是映射到所有指示器的节点数和异常快照中的所有节点数)。表 9 显示了 K = 4 时每个 DARPA3 数据集的工作量减少情况。平均而言,指标生成器将安全分析师的工作量减少了 58%。相比之下,基线系统Unicorn只告诉快照是否异常,分析人员必须调查所有包含的节点。我们将 Unicorn 所有警报快照的节点数量相加,并显示在表 10 中。Unicorn 待调查的节点数量为 41343 个,是 PROGRAPHER 的 7.1 倍。
Unicorn的数值高于Total,因为Unicorn预测较大的快照为异常
# 运行性能评估
表 10 中显示了每个组件的运行时开销,其结果是在不同 DARPA3 数据集上的重复运行结果的平均值。
数据处理和训练。 平均而言,PROGRAPHER 需要 8.4 分钟来处理来自一个数据集的一天日志,并需要 8.3 微秒来生成快照序列。 PROGRAPHER 需要 6.29 小时来训练编码器模型 100 个 epoch。对于异常检测器,训练大约需要 20.6 分钟。
推理和指示器生成。 PROGRAPHER 平均花费 10.3 秒来预测异常快照,并花费 8.3 秒为每个异常快照生成排序的 RSG。
表明 PROGRAPHER 能够近乎实时地进行异常检测

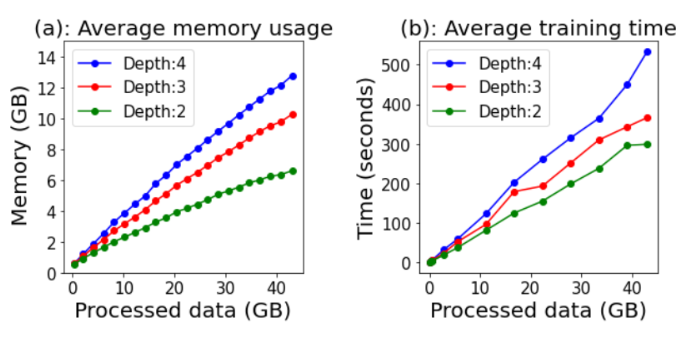
可扩展性。 本文首先通过改变训练图的数量来测量内存消耗如何随着数据量的增长而增长。对于相同的数据大小,WL 内核的深度 (d) 影响最大,因此将其值从 2 更改为 4,图 4(a) 显示了数据量和内存消耗之间的关系。由于 PROGRAPHER 对快照而不是整个数据集执行训练和推理,因此内存消耗与数据量呈次线性关系。例如,即使在 d 设置为 4 的情况下处理 40 GB 数据,最大内存使用量也是 12.7 GB,其中 10.2 GB 用于训练和存储嵌入。在图 6(b) 中显示每个 epoch 的时耗,时耗与数据量呈线性关系,仅当 d = 4 并且数据大小超过 30GB 时,时耗增加得更快。
# 其他实验
本文使用相对较小数据集 StreamSpot-DS(8.3GB)来分析关键参数对 PROGRAPHER 有效性的影响。使用ATLAS-DS数据集,通过在攻击事件之前和之后插入许多随机事件模仿逃避攻击对 PROGRAPHER 进行鲁棒性测试。
# 研究趋势
正常行为的改变。 由于 PROGRAPHER 被设计为溯源图上的异常检测系统,因此当观察到未见的行为时,它会发出警报。然而,正常行为的变化(例如,员工登录到新的内部服务器)可能被视为异常,这可能会引入误报。这个问题可以看作是概念漂移问题,可以通过使用更新的数据重新训练 PROGRAPHER 来部分缓解。检测概念漂移何时发生至关重要,这样就不需要频繁执行成本高昂的重新训练。
直推式和归纳式学习。 PROGRAPHER当前的设计遵循直推式学习模式,假设测试阶段的所有RSG都已在训练阶段被看到。当遇到新的 RSG 时,PROGRAPHER 必须重新训练。尽管本文通过仅使用节点和边类型构建 RSG 来减少看到新 RSG 的机会,但在生产环境中仍然需要重新训练。这种限制也存在于现有的基于图学习的安全系统中,如 Euler 和 ShadeWatcher 中。为了解决这个问题,未来研究可以探索归纳式学习模式,该模式能够从其邻域动态生成新节点的嵌入,而无需重新训练。然而,在这种情况下,必须选择不同的编码器模型,例如 GraphSage。
更具适应性的攻击。 一种有效的对抗策略是注入重复事件来填充用于构建快照的缓存,本文实验中发现 CLEARSCOPE 数据集上的漏报是由事件聚合引起的,该问题存在于其他事件聚合的溯源系统中(例如 ShadeWatcher )。一种可能的解决方案是在事件聚合后保留更多信息(例如,某些事件字段的分布)。
# 文献比对分析
# 基于学习的溯源分析
当目标是边/节点时,训练后的系统旨在判断一对实体之间的交互或实体本身是否是恶意的。 ShadeWatcher 根据系统日志构建知识图并使用基于图神经网络(GNN)的推荐系统来检测恶意交互。SIGL 利用节点嵌入和自动编码器模型来判断从软件安装图 (SIG) 生成的进程是否是恶意的。然而,当遇到大的溯源图时,实现基于边/节点的高精度检测是相当具有挑战性的。此外,检测结果不提供对于理解攻击活动有价值的上下文信息(例如,与检测到的边/节点相关的其他活动)。
但是Flash一文中表示ShadeWatcher 是可以提供上下文相关信息的
ShadeWatcher 实现了很高的检测精度,但它是针对小图进行评估的(大多数图只有数百个交互)
SIGL 检查的 SIG 通常很小
对于基于路径的检测,从来源图中选择符合某些模式(例如,与 POI 节点关联)的路径,并且经过训练的系统对路径进行分类。例如,ProvDetector 通过应用词嵌入将执行路径转换为向量,然后对它们进行聚类来识别隐蔽恶意软件。 Atlas应用词形还原和词嵌入来生成序列,并使用长短期记忆(LSTM)网络来预测序列是否与攻击相关。然而,这些方法首先依赖于启发式方法选择 POI 路径(ProvDetector 选择针对隐蔽恶意软件定制的罕见路径)或节点(ATLAS 假设一些恶意节点已知),然后应用基于学习的方法。
对于基于图的检测,溯源图要么被分类为一个整体,要么被分解为一组子图,并在这些子图上执行分类。例如,Unicorn 通过滑动时间窗口对日志进行切片,并从中构造演化子图。对于每个子图,graph sketching将捕获结构特征的直方图转换为固定大小的向量。 ProvGem 提出多重嵌入来捕获节点的不同上下文,并以监督学习的方式对聚合节点嵌入上的图进行分类。基于图的检测的主要问题是其检测粒度太粗,分析人员仍然需要付出相当大的精力才能从可能包括数千个节点的图中查明恶意实体/事件。
HERCULE 使用半监督社区检测算法来关联攻击事件并重建攻击。 Streamspot通过广度优先搜索(BFS)提取局部图特征并对快照进行聚类以检测异常特征。 P-Gaussian应用高斯分布原理来计算入侵行为及其变异体之间的相似度。 Log2vec 从日志构建异构图并应用图嵌入来检测异常活动。
# 基于启发式的溯源分析
基于启发式的起源分析。为了解决“依赖爆炸”问题,另一个方向是应用人工编写的规则来确定调查的优先级,许多先前的工作从 POI 事件中执行图遍历(例如,广度优先搜索),并根据规则选择可疑路径。例如,NoDoze 使用历史信息为溯源图中的警报分配威胁分数,然后识别异常路径。 PrioTracker 通过计算事件的稀有度分数来确定异常事件的优先级,从而加速前向跟踪 。 Padoga 考虑单个路径和整个溯源图的异常程度来识别入侵。 SLEUTH 和 Morse 使用基于标签的信息流技术来重建攻击场景 。
分析人员使用攻击签名(例如妥协指标 (IoC))查询溯源图,并分析类似的子图。 $\tau$-calculus 提出了一种新的领域特定语言(DSL),使威胁分析师的查询更加直观和高效。Poirot模型将该问题建模为图模式匹配(GPM)问题,并为其提出了一种新的图对齐方法。
一些工作从细粒度的来源图中提取摘要图以简化调查。 RapSheet 和 Holmes 依靠对抗性策略、技术和程序 (TTP) 的知识库来构建摘要图。 DepComm 总结了基于以流程为中心的社区的溯源图,并提取了用于攻击调查的信息路径。
# 日志异常检测
PROGRAPHER 依赖于 graph2vec,它采用了 doc2vec 和 word2vec 等 NLP 技术来进行图嵌入。类似的NLP技术也被应用于检测异常日志。 Deeplog 将审计日志视为句子,并利用 LSTM 模型来检测异常事件。 LogAnomaly应用word2vec提取隐藏在日志模板中的语义信息来检测日志异常。 Attack2Vec 使用时间词嵌入来建模和跟踪攻击步骤的演变。
# reference
本部分仅列出本人认为较为重要且与本文工作密切相关的参考文献
[1] Abdulellah Alsaheel, Yuhong Nan, Shiqing Ma, Le Yu, Gregory Walkup, Z. Berkay Celik, Xiangyu Zhang, and Dongyan Xu. ATLAS: A sequence-based learning approach for attack investigation. In Michael Bailey and Rachel Greenstadt, editors, USENIX Security Symposium, pages 3005–3022. USENIX Association, 2021.
[2] Xueyuan Han, Thomas F. J.-M. Pasquier, Adam Bates, James Mickens, and Margo I. Seltzer. UNICORN: runtime provenance-based detector for advanced persistent threats. CoRR, abs/2001.01525, 2020.
[3] Qi Wang, Wajih Ul Hassan, Ding Li, Kangkook Jee, Xiao Yu, Kexuan Zou, Junghwan Rhee, Zhengzhang Chen, Wei Cheng, Carl A. Gunter, and Haifeng Chen. You are what you do: Hunting stealthy malware via data provenance analysis. In NDSS. The Internet Society, 2020.
[4] J. Zeng, X. Wang, J. Liu, Y. Chen, Z. Liang, T. Chua, and Z. Chua. Shadewatcher: Recommendation-guided cyber threat analysis using system audit records. In 2022 IEEE Symposium on Security and Privacy (SP) (SP), 2022.
[5] Daniel Arp, Erwin Quiring, Feargus Pendlebury, Alexander Warnecke, Fabio Pierazzi, Christian Wressnegger, Lorenzo Cavallaro, and Konrad Rieck. Dos and don’ts of machine learning in computer security. In Proc. of the USENIX Security Symposium, 2022.
[6] Wajih Ul Hassan, Adam Bates, and Daniel Marino. Tactical provenance analysis for endpoint detection and response systems. In IEEE Symposium on Security and Privacy, pages 1172–1189. IEEE, 2020.
[7] Sadegh Momeni Milajerdi, Rigel Gjomemo, Birhanu Eshete, R. Sekar, and V. N. Venkatakrishnan. HOLMES: real-time APT detection through correlation of suspicious information flows. In IEEE Symposium on Security and Privacy, pages 1137–1152. IEEE, 2019.
[8] Z. Xu, P. Fang, C. Liu, X. Xiao, Y. Wen, and D. Meng. Depcomm: Graph summarization on system audit logs for attack investigation. In 2022 2022 IEEE Symposium on Security and Privacy (SP) (SP), 2022.
# 独创声明
本文为本人UCAS的课程论文阅读报告,禁止转载!!!
本文为本人UCAS的课程论文阅读报告,禁止转载!!!
本文为本人UCAS的课程论文阅读报告,禁止转载!!!