# 通过关系蒸馏进行无链接链路预测
图神经网络(GNN)在链路预测任务中表现出了卓越的性能。尽管图形神经网络非常有效,但其非三角邻域数据依赖性带来的高延迟限制了图形神经网络的实际部署。相反,由于缺乏关系知识,已知的高效 MLP 的效果远不如 GNN。在这项工作中,为了结合 GNN 和 MLP 的优势,我们首先探索了用于链接预测的直接知识提炼(KD)方法,即基于预测 logit 的匹配和基于节点表示的匹配。在观察到直接 KD 类似方法在链接预测中的表现不佳后,我们提出了一种关系 KD 框架,即无链接链接预测(LLP),以利用 MLP 对链接预测进行知识提炼。与匹配独立链接对数或节点表示的简单 KD 方法不同,LLP 将以每个(锚)节点为中心的关系知识提炼到学生 MLP 中。具体来说,我们提出了基于等级的匹配和基于分布的匹配策略,两者相辅相成。广泛的实验证明,LLP 显著提高了 MLP 的链接预测性能,甚至在 8 项基准测试中的 7 项测试中,LLP 的表现优于教师 GNN。在大规模 OGB 数据集上,LLP 的链接预测推理速度比 GNN 提高了 70.68 倍。
# 引言
图神经网络(GNN)已被广泛用于图结构数据的机器学习(Kipf & Welling、2016a; Hamilton 等人,2017)。它们在节点分类(Veliˇ ckovi ́ c 等人,2017 年;Chen 等人,2020 年)、图分类(Zhang 等人,2018 年)、图生成(You 等人,2018 年;Shiao & Papalexakis,2021 年)和链接预测(Zhang & Chen,2018 年;Shiao 等人,2023 年)等各种应用中表现出了显著的性能。
其中,链接预测是图机器学习领域一个显著的关键问题,其目的是预测任意两个节点形成链接的可能性。它有着广泛的实际应用,如知识图谱的完成(Schlichtkrull 等人,2018;Nathani 等人,2019;Vashishth 等人,2020)、社交平台上的好友推荐(Sankar 等人,2021;Tang 等人,2022;Fan 等人,2022)以及服务和商务平台上的用户项目推荐(Koren 等人,2009;Ying 等人,2018a;He 等人,2020)。随着 GNN 的日益普及,最先进的链接预测方法采用了编码器-解码器式模型,其中编码器是 GNN,解码器直接应用于由 GNN 学习到的节点表示对(Kipf & Welling, 2016b;Zhang & Chen, 2018;Cai & Ji, 2020;Zhao 等人,2022b)。
GNN 的成功通常归功于明确使用了节点周围邻域的上下文信息(Zhang 等人,2020e)。然而,与多层感知器(MLP)等表格式模型相比,这导致了对邻域获取和聚合方案的严重依赖,特别是由于邻域爆炸,会导致训练和推理的时间成本很高(Zhang 等,2020b;Jia 等,2020;Zhang 等,2021b;Zeng 等,2019)。与 GNNs 相比,MLPs 不需要任何图拓扑信息,因此更适用于新节点或孤立节点(如冷启动设置),但通常会导致编码器的一般任务性能较差,这一点我们在第 4 节中也进行了实证验证。尽管如此,与 GNN 相比,没有图依赖性使得 MLP 的训练和推理时间可以忽略不计。因此,在需要快速实时推理的大规模应用中,MLP 仍然是一个主要选择(Zhang 等人,2021b;Covington 等人,2016;Gholami 等人,2021)。
鉴于这些速度与性能的权衡,最近有几项研究提出利用知识蒸馏(KD)技术将所学知识从 GNN 转移到 MLP(Hinton et al., 2015; Zhang et al., 2021b; Zheng et al.,2021; Hu et al., 2021))以利用 GNN 的性能优势和 MLP 的速度优势。具体来说,通过这种方式,学生 MLP 有可能从 GNN 教师那里获得通过 KD 传播的图语境知识,从而不仅在实践中表现更好,而且还能享受到与 GNN 相比的模型延迟优势,例如在生产推理设置中。不过,这些研究主要集中在节点或图层任务上。鉴于链接预测任务中的 KD 尚未得到探索,而推荐系统中存在大量的链接预测问题,我们的工作旨在弥补这一关键差距。具体来说,我们的问题是:
我们能否从 GNN 中有效地提炼出与 MLP 相关的链接预测知识?
在这项工作中,我们重点探索、借鉴并提出了针对链接预测设置的跨模型(GNN 到 MLP)提炼技术。我们首先探索了两种直接对齐学生和教师的 KD 方法:(i) 基于对数的链接存在概率预测匹配(Hinton 等人,2015 年),以及 (ii) 基于生成的潜在节点表征的表征匹配(Gou 等人,2021 年)。然而,根据经验,我们发现无论是基于对数的匹配还是基于表征的匹配都不足以提炼出足够的知识,使学生模型在链接预测任务中表现出色。我们假设,这两种 KD 方法表现不佳的原因是,链接预测与节点分类不同,在很大程度上依赖于关系图拓扑信息(Mart ́ınez 等人,2016;Zhang & Chen,2018;Yun 等人,2021;Zhao 等人,2022b),而直接方法并不能很好地捕捉这些信息。
为了解决这个问题,我们提出了一个关系 KD 框架,即 LLP:我们的主要直觉是,我们不关注单个节点对或节点表示的匹配,而是关注每个(锚)节点与图中其他(上下文)节点之间关系的匹配。鉴于以锚节点为中心的关系知识,即教师模型预测的锚节点与每个上下文节点之间的链接存在概率,LLP 通过两种匹配方法将其提炼到学生模型中:(i) 基于等级的匹配和 (ii) 基于分布的匹配。更具体地说,基于等级的匹配为学生模型提供了所有上下文节点相对于锚节点的等级损失,保留了与下游链接预测用例直接相关的关键等级信息,例如用户上下文好友推荐(Sankar 等,2021;Tang 等,2022)或项目推荐(Ying 等,2018a;He 等,2020)。另一方面,基于分布的匹配为学生模型提供了以锚节点为条件的上下文节点的链接概率分布。重要的是,基于分布的匹配是对基于等级的匹配的补充,因为它提供了关于概率相对值和差异大小的辅助信息。为了全面评估我们提出的 LLP 的有效性,我们在 8 个公共基准上进行了实验。除了图任务的标准转导设置外,我们还设计了一个更现实的设置,模仿链接预测的现实(在线)用例,我们称之为生产设置。在所有数据集上,LLP 在转导设置下平均比独立 MLP 高出 18.18 分,在生产设置下平均比独立 MLP 高出 12.01 分;在转导设置下,LLP 在 7/8 个数据集上的表现与教师 GNN 相当或更胜一筹。令人欣慰的是,在冷启动节点上,LLP 平均分别比教师 GNN 和独立 MLP 高出 25.29 和 9.42 Hits@20。最后,LLP 的推断速度大大快于 GNNs,例如在大型 Collab 数据集上快了 70.68 倍。
# 相关工作和背景
使用 GNN 进行链接预测。在这项工作中,我们将常用的编码器-解码器框架用于链接预测任务(Kipf & Welling, 2016b;Berg 等人,2017;Schlichtkrull 等人,2018;Ying 等人,2018a;Davidson 等人,2018;Zhu 等人,2021;Yun 等人,2021;Zhao 等人,2022b),其中基于 GNN 的编码器学习节点表示,解码器预测链接存在概率。大多数 GNN 在消息传递框架下运行,模型通过获取邻居的信息迭代更新每个节点 i 的表示 hi。也就是说,节点在第 l 层的表示是通过聚合学习操作和更新操作:
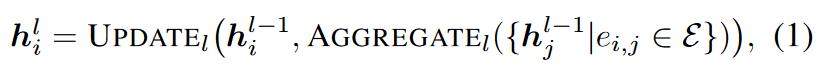
其中,AGGREGATE 组合或汇集本地邻居特征,UPDATE 是可学习的变换$h_i^0=x_i$。链接预测解码器利用上一层的节点表示,即 i∈V 的 hi,来预测节点对 i 和 j 之间的链接概率:
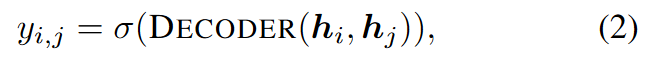
其中 σ 表示Sigmoid运算。在这项工作中,根据大多数最先进的链接预测文献(Zhang 等人,2021a;Tsitsulin 等人,2018;Zhao 等人,2022b;Wang 等人,2021),我们将 Hadamard 乘积和 MLP 作为所有方法的链接预测 DECODER。
GNN的知识蒸馏。知识蒸馏(KD)旨在将知识从高容量和高准确性的教师模型转移到轻量级学生模型,通常在资源受限的环境中使用。KD方法已显示出在显著降低模型复杂性的同时,几乎不会牺牲任务性能的潜力。由于GNNs因邻居聚合引起的数据依赖性而速度较慢,基于图的KD方法通常将GNNs蒸馏到MLPs上,后者由于其显著提高的效率和可扩展性,在大规模工业应用中得到广泛应用。例如,Zheng等人提出了一种基于KD的框架,重新发现MLPs缺失的图结构信息,这提高了模型在冷启动节点上的节点分类任务的泛化能力。现有的基于图数据的KD方法主要关注节点级别和图级别任务,而将KD应用于链接预测尚未被探索。我们的工作专注于从GNN教师向MLP学生中提取链接预测相关信息,并研究各种KD策略以对齐学生和教师的预测。
# 跨模型知识蒸馏用于链接预测
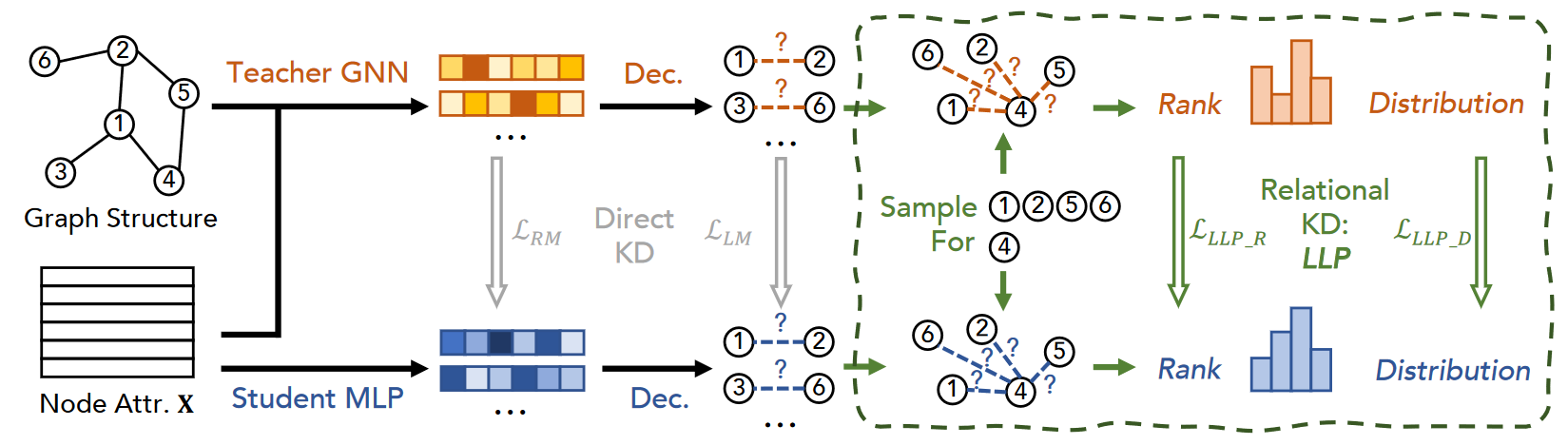
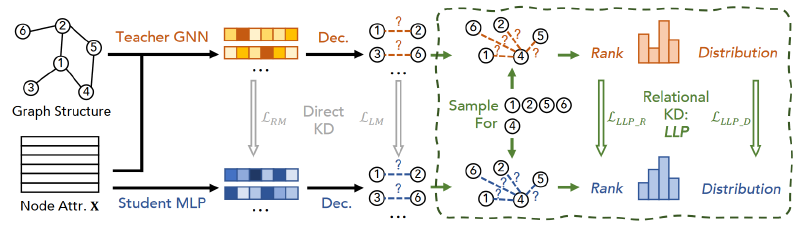
在本节中,我们提出并讨论了几种跨模型从教师GNN到学生MLP的知识蒸馏方法,用于链接预测的目的。在所有情况下,我们的目标是使用由GNN教师产生的工件来指导学生MLP,除了任何可用的训练标签(关于链接存在的ai,j)。我们首先采用两种直接的知识蒸馏(KD)方法:基于逻辑匹配和基于表示匹配,将它们适应到链接预测任务中;我们称这些方法为直接的,因为它们涉及直接匹配教师和学生之间的样本预测。接下来,我们提出并介绍了我们提出的关系KD框架,LLP(Linkless Link Prediction),并提出了两种匹配策略,以将额外的拓扑结构信息蒸馏到学生模型中。我们称这些方法为关系的,因为它们要求在教师和学生之间保持跨样本的关系(Park等人,2019)。图1总结了我们的提议。
# 直接方法
逻辑匹配是一种直接的策略,用于从教师到学生的知识蒸馏,其中它直接旨在教导学生在下游任务上像教师一样概括。它由Hinton等人(2015)提出,并且仍然是各种任务中最广泛使用的KD方法之一。Phuong和Lampert(2019)以及Ji和Zhu(2020)从理论上分析了它的有效性。此外,它也被证明在图数据上的知识转移是有效的。例如,Zhang等人(2021b)使用教师GNN生成的软逻辑来指导学生MLP,并在节点分类任务上取得了强大的性能。类似地,我们为候选边(i, j)生成软分数yi,j,并训练学生使其预测ˆyi,j与此目标匹配:
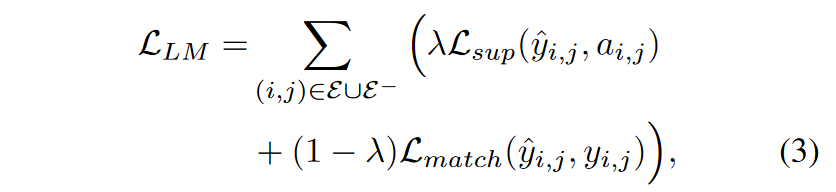
表示匹配是另一种直接的蒸馏方法,我们旨在对齐学生学到的潜在节点嵌入空间与教师的。由于这种KD训练信号只优化学生模型的编码器部分,所以它必须与Lsup一起使用,以便学生解码器也能接收梯度并被优化:
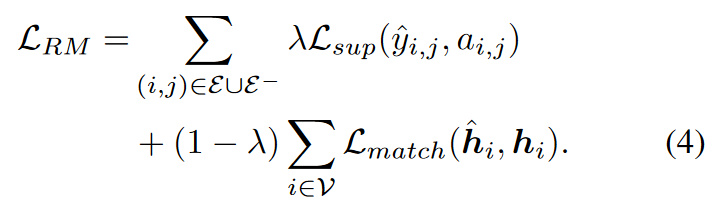
# 关系蒸馏的链接预测
动机。上述直接方法要求学生模型直接匹配节点级或链接级的工件。然而,人们可能会问:对于链接预测任务来说,匹配这些是否足够?这在考虑大多数链接预测应用涉及任务的上下文中尤其相关,其中对源节点或锚点节点的候选目标进行排名是感兴趣的任务,即在用户-项目图中,预测器必须从用户的角度对一组候选项目进行排名。这些上下文涉及同时对多个关系或链接级样本进行推理,表明跨这些关系的匹配可能比直接的节点级或链接级方法更符合目标链接预测任务。
此外,一些作品(Zhang & Chen, 2018; Yun等人,2021)表明,图结构信息对链接预测任务至关重要。例如,启发式链接预测方法通常显示出与GNNs相比具有竞争力的性能,并且在神经图方法之前一直是准确链接预测的基石。大多数启发式方法仅基于图结构信息(例如,共同邻居和最短路径)来衡量目标节点对的分数。此外,一些最近的工作(Zhang & Chen, 2017, 2018; Li等人,2020; Zhao等人,2022b)也表明,包含拓扑信息,如局部子图、与锚点节点的距离或增强链接,可以大幅提高GNNs在链接级任务上的性能。观察到大多数成功的链接预测方法都涉及使用关系信息而不仅仅是两个节点,我们也在蒸馏背景下采用这种直觉,并提出我们的关系KD用于链接预测。
# 无连接链接预测
根据我们关于保持关系知识的直观理解,我们提出了一个新的关系蒸馏框架,称为Linkless Link Prediction,或LLP。与专注于匹配单个节点对分数或节点表示不同,LLP专注于蒸馏每个节点在图中与其他节点的关系知识;我们将前者称为锚点节点,后者称为上下文节点。对于图中的每个节点,当它作为锚点节点时,我们的目标是为学生MLP模型提供其与一组上下文节点的关系知识。每个节点可以作为锚点节点,也可以作为其他锚点节点的上下文节点。
设v表示锚点节点,Cv表示v对应的上下文节点集合。我们表示教师模型预测的v与Cv中每个节点之间的概率为Yv = {yv,i | i ∈ Cv}。同样,我们表示学生模型对这些的预测为Yv = {yv,i | i ∈ Cv}。为了有效地从Yv到Yv蒸馏关系知识,我们提出了两种关系匹配目标来训练LLP:基于排名的匹配和基于分布的匹配,我们将在下文中介绍。
基于排名的匹配(Rank-based Matching)。如第3.2节所述,链接预测通常被视为一个排名任务,要求模型根据一个种子节点对相关候选项进行排名,例如在用户-项目图设置中,预测器必须从用户的角度对一组候选项目进行排名。因此,我们认为,与匹配独立的逻辑不同,匹配由教师引起的排名可以更直接地教会学生关于上下文节点相对于锚点节点的关系知识。例如,对于特定用户,项目A应该排在项目C之前,项目C应该排在项目B之前。为了将这种基于排名的直觉纳入训练目标,我们采用了修改后的基于边际的排名损失,用教师GNN的排名对数来训练学生。具体来说,我们枚举𝑌^𝑣Y^v中所有预测概率的对,并用𝑌𝑣Y**v中的相应对进行监督。即:
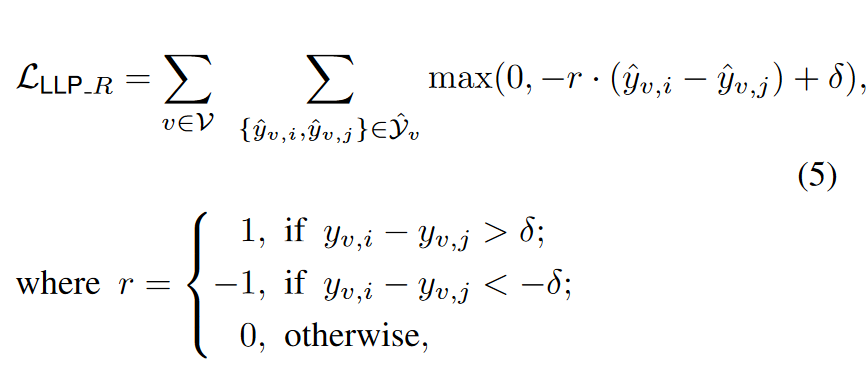
δ是边际超参数,通常是一个非常小的值(例如0.05)。注意,上述损失与传统的基于边际的排名损失不同,因为它在教师GNN给出相似概率的对数对上有一个𝑟=0r=0的条件(导致恒定损失),即∣𝑦𝑣,𝑖−𝑦𝑣,𝑗∣<𝛿∣y**v,i−y**v,j∣<δ。这种设计有效地防止了学生模型试图区分教师可能由于噪声而产生的微小概率差异;如果没有这个条件,损失将传递二元信息,而不考虑差异有多小。我们还通过表D.16的经验性地展示了这种设计的必要性。
基于分布的匹配(Distribution-based Matching)。虽然基于排名的匹配可以有效地教会学生模型关系排名信息,我们观察到它并没有充分利用𝑌𝑣Y**v中的值信息。例如,对于特定用户,项目A应该比项目C排名高得多,项目C应该只比项目B略高。尽管第3.1节中介绍的逻辑匹配似乎适合这里,我们观察到它的链接级匹配策略只便于匹配分散的节点对上的信息,而不是集中在锚点节点上的上下文关系上——从经验上,我们也发现它的效果有限。因此,为了实现以锚点节点为中心的关系值匹配,我们进一步提出了一个基于分布的匹配方案,它利用教师预测𝑌𝑣Y**v和学生预测𝑌^𝑣Y^v之间的KL散度,以每个锚点节点𝑣v为中心。具体来说,我们定义它为:
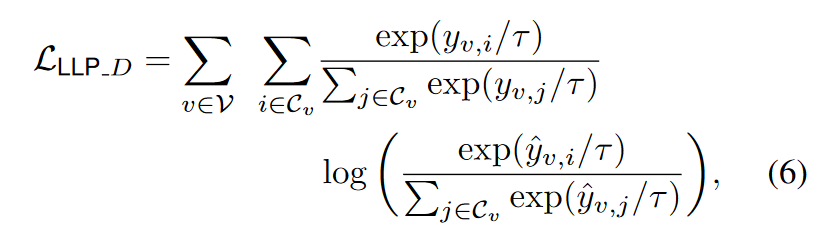
在训练 LLP 时,除了地面实况标签损失外,我们还联合优化了基于排名的匹配损失和基于分布的匹配损失。因此,LLP 对学生采用的总体训练损失为
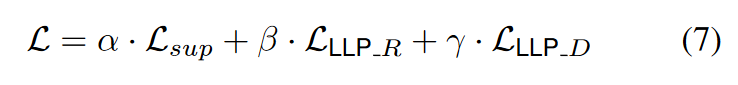
# 实验评估
# 实验设置
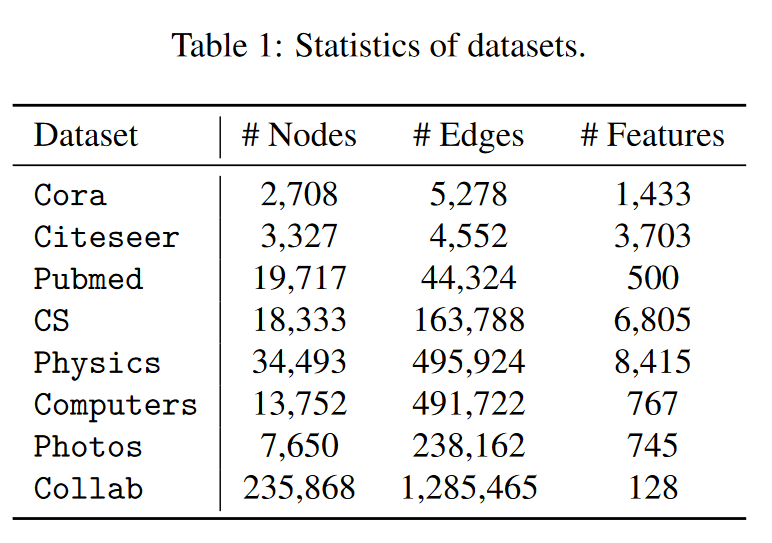
评估设置。为了在链接预测任务中全面评估我们提出的 LLP 和基线方法,我们在转导和生产设置中进行了实验。对于转导设置,图中的所有节点都可以在训练集/验证集/测试集中观察到。根据之前的研究(Zhang & Chen,2018;Chami 等人,2019;Cai 等人,2021),我们从图中随机抽取 5%/15% 的链接,这些链接的无边节点对数量与非 OGB 数据集上的验证集/测试集相同。验证/测试链接将从训练图中屏蔽掉。对于 OGB 数据集,我们遵循其官方的训练/验证/测试拆分方法(Wang 等人,2020a)。除了过渡性设置外,我们还设计了一种更现实的设置来模拟实际的链接预测用例,我们称之为生产设置。在生产环境中,新节点会出现在测试集中,而训练集和验证集只观察以前存在的节点。因此,在这种情况下,测试集中会出现三类节点对(边或无边):现有-现有、现有-新、新-新,其中第一类类似于转导式设置中的测试边,后两类则类似于最近一些研究中使用的归纳式设置(Bojchevski & G ̈ unnemann, 2017; Hao et al., 2020; Chen et al., 2021b)。然而,在实际应用案例中,例如社交网络或在线平台的增长,这三类边缘都会以不同的比例出现,因此我们对这三类边缘都进行了评估。请注意,我们只在非 OGB 数据集上进行生产环境实验,因为 OGB 数据集在其公开发布的版本中已经进行了时间分割。我们将在附录 C 中进一步阐述生产环境的细节。
# 链接预测结果
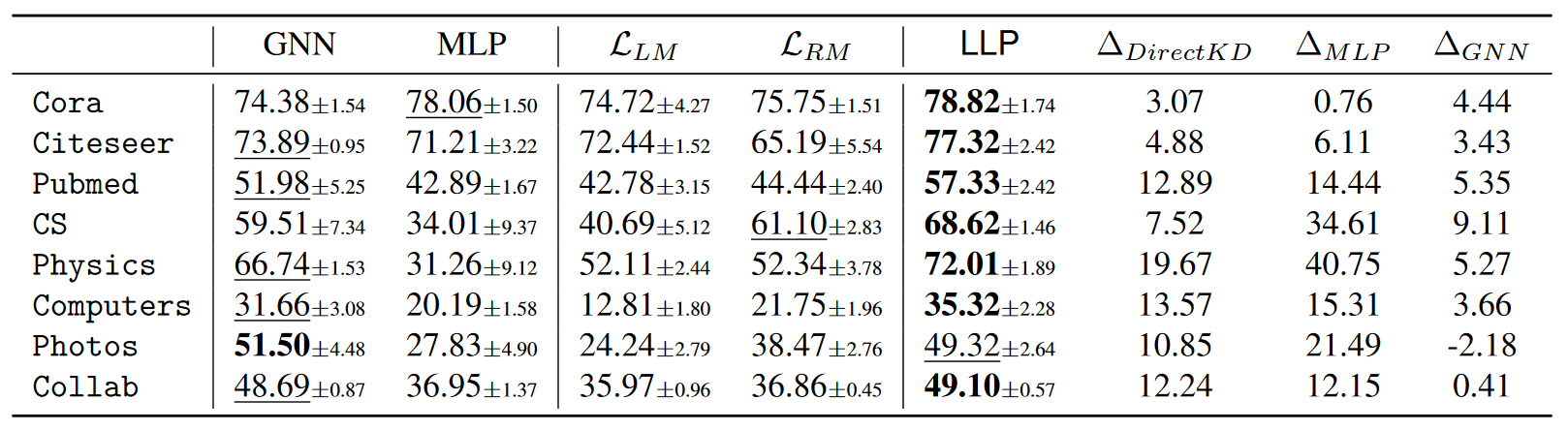
Transductive Setting(归纳设置)
- 这是链接预测中的一个标准设置,其中训练、验证和测试集中的所有节点在训练图上都是可见的,但是一部分正链接被遮蔽用于验证和测试集。
- 在这种设置下,模型在训练期间可以看到整个图的结构,包括所有的节点和边,除了那些被明确遮蔽用于评估的链接。
从表 2 中,我们还发现在某些数据集上,LLP 的性能比教师 GNN 有了显著提高。我们假设,导致这种改进的原因有两个。其一,当节点特征对链接预测具有足够的信息量时,学生 MLP 模型已经具备了显著的学习能力。例如,在 Cora 数据集上,MLP 已经可以产生比 GNN 更好的预测性能。另一个原因是关系 KD 提供了从 GNN 到 MLP 的关系结构知识,这为 MLP 提供了额外的有价值的知识。最近关于知识提炼的研究(Allen-Zhu & Li,2020;Guo 等人,2022)也有类似的发现,即结合不同模型的不同观点有助于提高模型的性能 。
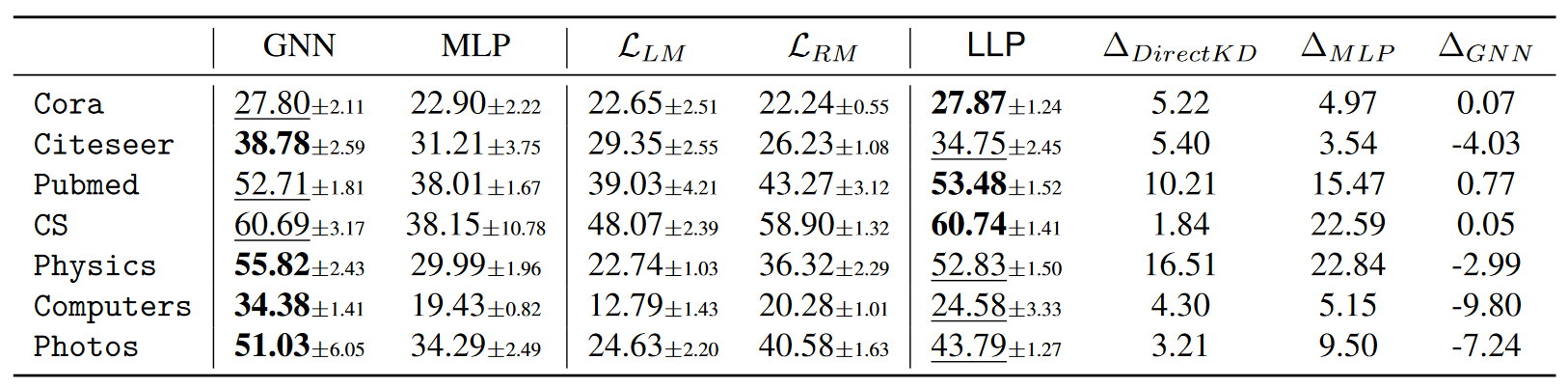
Production Setting(生产设置)
- 这是一种更接近实际应用场景的设置,模拟了实际链接预测用例,例如社交网络平台上的用户好友推荐,其中新用户和好友关系会频繁出现。
- 在生产设置中,测试集中可能会出现在训练阶段不可见的新节点和新边。这种设置考虑了三个类别的节点对:现有-现有、现有-新、新-新,分别对应于训练集中已经存在的节点对、至少一个新节点的节点对,以及完全由新节点组成的节点对。
# 推理速度
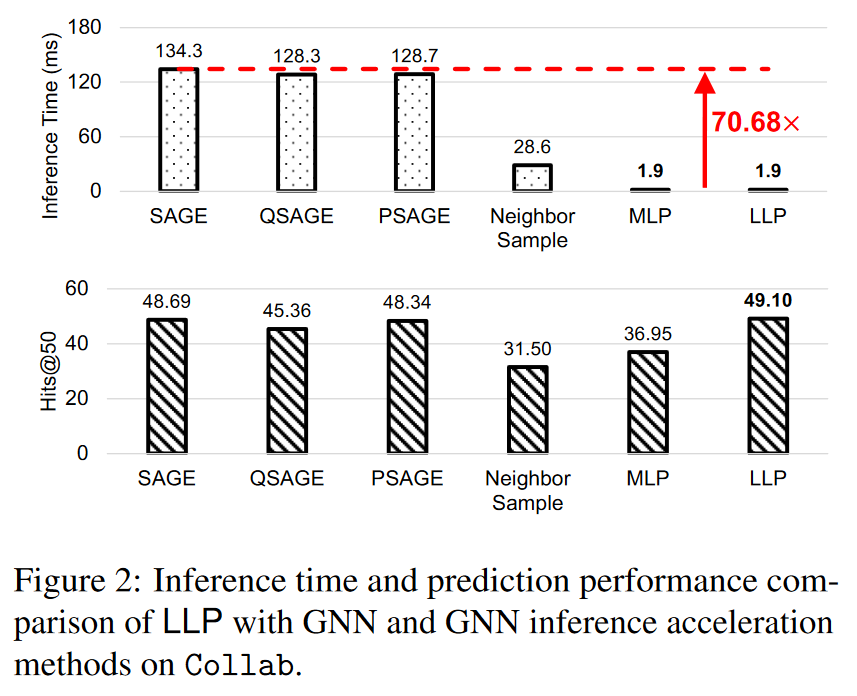
与其他常见的 GNN 推断加速方法相比,我们对 LLP 进行了评估,这些方法主要侧重于硬件和算法以减少计算消耗,例如剪枝(Zhou 等人,2021 年)和量化(Zhao 等人,2020 年;Tailor 等人,2020 年)。按照 Zhang 等人(2021b)的实验设置,我们测量了图中的归纳推理时间。我们针对 4 种常见的 GNN 推理加速方法进行了评估:(i) SAGE(Hamilton 等人,2017 年),(ii) 从 float32 到 int8 的量化 SAGE(QSAGE)(Zhao 等人,2020 年;Tailor 等人,2020 年),(iii) 去掉 50% 权重的 SAGE(PSAGE)(Zhou 等人,2021 年;Chen 等人,2021 年c),以及 (iv) 去掉 15 个扇出的邻居采样 SAGE。图 2 显示了大规模 OGB 数据集 Collab 的结果。我们可以看到,与 SAGE 相比,LLP 在 Collab 上的速度提高了 70.68 倍。与最佳加速方法 “邻居采样”(该方法可减少图依赖性,但不能像 LLP 那样消除图依赖性)相比,LLP 仍然实现了 15.05 倍的加速。这是因为所有这些推理加速方法仍然依赖于图结构。从图 2 的下图中,我们可以进一步观察到 LLP 的性能优于 GNN 和其他推理加速方法。
# 冷启动节点的链接预测结果
处理冷启动节点(新出现的无边节点)是推荐和信息检索应用中的一个常见挑战(Li 等人,2019 年;Zheng 等人,2021 年;Ding 等人,2021 年)。如果没有这些边,GNNs 就不能很好地发挥作用,因为它们在很大程度上依赖于邻居信息。另一方面,不使用任何图拓扑信息的 MLP 可以说更适合。在这里,我们模拟了冷启动设置,即在生产设置的测试阶段移除所有新边缘,即所有新出现的节点都被隔离(更多详情见附录 C)。表 4 显示了 LLP、独立 MLP 和教师 GNN 在冷启动节点上的表现。我们观察到,在 Hits@20 上,LLP 的平均性能一直优于 GNN 和 MLP,分别为 25.29 和 9.42。我们还在附录 D.8 中进一步比较了 LLP 与冷启动节点的另一项相关研究。
# 大规模数据集上的链接预测结果
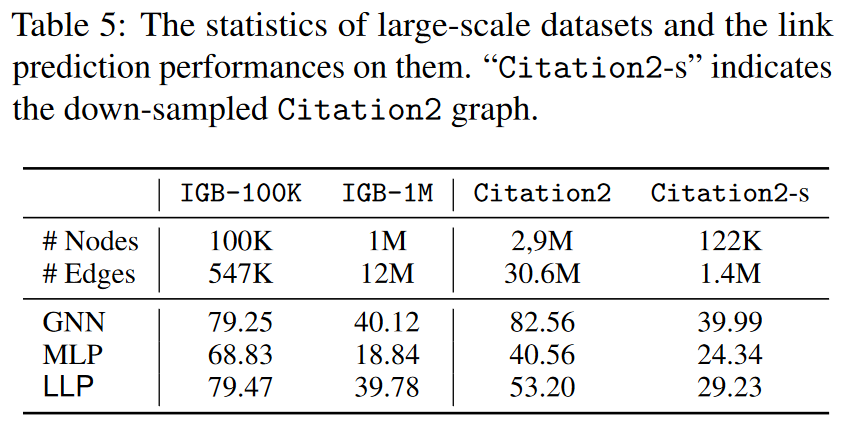
除了 Collab 之外,我们还在最近提出的三个大规模图基准上进行了实验:IGB-100K、IGB-1M(Khatua 等人,2023 年)和 Citation2(Wang 等人,2020a;Mikolov 等人,2013 年)。数据集统计和链接预测结果(Hits@200)如表 5 所示。在 IGB 数据集上,我们观察到 LLP 可以在这两个数据集上生成有竞争力的结果,这进一步证明了 LLP 有能力从大规模图中获取复杂的链接预测相关知识。另一方面,Citation2 的结果则显示出不同的模式。虽然 LLP 的表现明显优于 MLP,但与 GNN 相比,其性能仍有很大差距。
我们假设,Citation2 上的不同性能模式是由于数据集的独特分布造成的。为了验证我们的假设,我们进一步在 Citation2 的采样版本(表 5 中的 “Citation2-s “列)上进行了实验。具体来说,我们对 Citation2 进行了缩减采样,以生成一个更小的版本(大小与 Collab 类似)。我们使用了基于随机漫步的抽样方法,事实证明这种方法能够保持原始图的属性(Leskovec & Faloutsos, 2006)。从表 5 中,我们观察到 Citation2 和 Citation2-s 的性能模式非常相似,这验证了我们的假设,即 LLP 和 GNN 之间的性能差距是由数据集自身的分布造成的,而不是由图的大小等其他因素造成的。在比较表 2 中照片和 Collab 的结果时,我们也发现了类似的情况,但情况正好相反:在较大的数据集(Collab)上,LLP 的表现优于 GNN,但在较小的数据集(Photos)上,LLP 的表现略逊于 GNN。总之,在不同的数据集上,LLP 的有效性可能会有所不同,但对图形的大小并不敏感。
# 消融实验
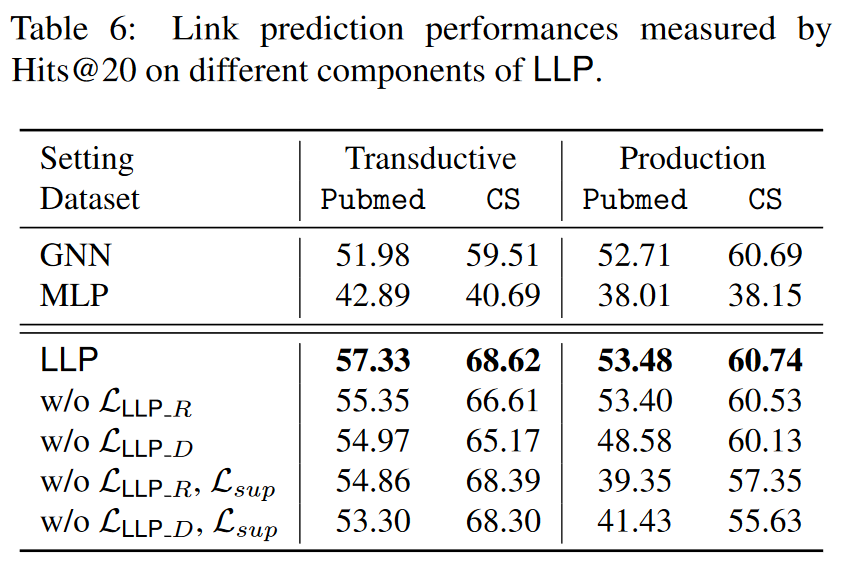
LLLP R 和 LLLP D 的有效性。由于我们提出的 LLP 包含两种匹配策略,即基于等级的匹配和基于分布的匹配,因此我们通过将它们从 LLP 中移除来评估它们的有效性。此外,我们还通过去除 Lsup 进行了进一步评估,即仅使用其中一种匹配损失作为 LLP 的总体损失。表 6 显示了这些设置与完全 LLP、独立 MLP 和教师 GNN 在 Pubmed 和 CS 数据集上的性能比较结果。我们注意到,基于等级的匹配和基于分布的匹配都对整体性能有很大贡献。在转导式设置中,两个损失项本身(最下面两行)的性能就已经超过了教师 GNN。
在生产环境中,单独的匹配损失性能优于 MLP,并且在添加 Lsup 后可以达到与 GNN 相当的性能。总之,基于等级的匹配和基于分布的匹配都能有效地提炼关系知识,并通过互补达到最佳性能。
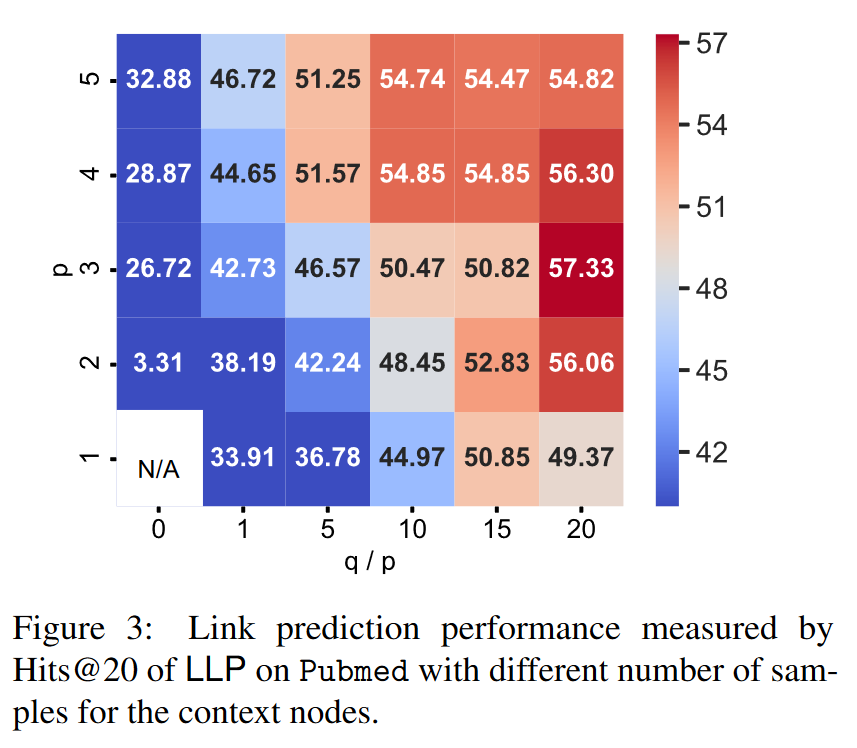
图 3 显示了 LLP 在不同上下文节点样本数(p 局部样本和 q 随机样本)下,在 Pubmed 上的链接预测性能。为便于调整超参数,我们将 q 设为 p 的倍数,如图 3 的 x 轴所示。我们观察到,随机样本数量较少的 LLP 的链接预测性能较差,这表明保留全局关系对于所提议的关系 KD 是必要的。一般来说,热图显示了一个清晰的趋势,使最佳值易于定位。
# 总结
我们的工作是解决与大规模应用 GNN 进行链接预测有关的问题。我们注意到,由于非三维数据依赖性,这些模型在推理时具有较高的延迟。为此,我们探索了从教师 GNN 到学生 MLP 模型的跨模型提炼方法,这种方法在推理时间上具有优势。我们首先将两种直接对数匹配和表示匹配 KD 方法应用到链接预测中,并观察到它们的不适用性。作为回应,我们引入了关系 KD 框架 LLP,该框架提出了基于等级的匹配和基于分布的匹配目标,两者相辅相成,迫使学生保留锚节点间上下文关系的关键信息。我们的实验表明,LLP 实现了 MLP 级别的提速(比 GNN 高出 70.68 倍),同时在转导和生产设置中,链接预测性能比 MLP 分别提高了 18.18 和 12.01 个百分点,在转导设置中的 7/8 个数据集和生产设置中的 3/6 个数据集中,LLP 的性能与教师 GNN 相当或优于教师 GNN,并且对冷启动节点的 Hits@20 改进显著提高了 25.29 个百分点。